再以后的一段日子的,我们将会学习 Android 上 Graphics 架构的一些组件, 将会从地层到上层的顺序。今天是一个概述。
底层的组件
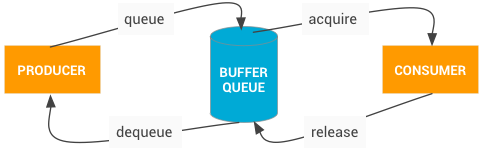
BufferQueue 和 Gralloc
BufferQueue 实现连接图形缓冲的生产者和消费者,消费者主要时接受了数据后,显示出来或者做进一步的处理。
gralloc 负责分配缓冲,通过 HAL 接口实现
SurfaceFlinger, Hardware Composer 和 virtual displays
SurfaceFlinger 从多个源接受数据, 混合后发送显示
HWC(Hardware Composer) 决定使用最有效的方式来混合图像
virtual display 让混合后的图像再系统内可用,比如录屏
Surface, Canvas 和 SurfaceHolder
Surface 生成一个对应的缓冲队列, 当再一个 Surface 上绘制时,最后结果会被传给消费者
Canvas API 是一套软件实现的绘制接口(支持硬件加速),负责往 Surface 上绘制
所有与视图相关的的操作,都会有一个 SurfaceHolder, 通过它来获取或者设置 Surface 的参数比如 大小, 格式
EGLSurface, OpenGL ES
OpenGL ES(GLES) 定义了一套图形渲染的 API
EGL 是一个库,它被用来通过操作系统来创建 OpenGL 里的窗口
Vulkan
Vulkan 是有一个图形渲染的 API, 类似于 OpenGL, 它提供了工具再应用里创建高质量,实时的图像, 减少了 CPU 负载, 支持 SPIR-V Binary Intermediate 语言
上层的组件
SurfaceView 和 GLSurfaceView
SurfaceView 将一个 Surface 和 View 绑定, SurfaceView 的 View 由 SurfaceFlinger 混合。允许再单独的线程做渲染操作。
GLSurfaceView 提供了辅助类管理 EGL 上下文,线程间通讯,与 Activity 生命周期的交互。
SurfaceTexture
SurfaceTexture 将一个 Surface 和一个 Texture 绑定在一块来创建一个缓冲队列,应用作为这个缓冲队列的消费者。
当一个生产者产生了一个新缓存,它会将它入队,这时候你的应用就会得到通知,应用就会释放旧的缓冲区,获取新的。然后执行 EGL 操作,让新缓冲区成为一个 GLES 中的外部 texture。
TextureView
TexureView 将一个 View 和一个 SurfaceTexture 绑定。
TextureView 包裹了一个 SuraceTexture, 负责监听它,从其中获取新的缓冲区,作为它的数据源, 然后按照 View 的配置来渲染数据
View 的混合总是使用 GLES, 这意味着更新内容会导致其他 View 的重绘(这里不太明白)
明天: 每天一点点音视频_BufferQueue
参考 官方文档